I spent a few months teaching a laptop to read the Moon
In March 2025, a lander called IM-2 reached the lunar south pole and tipped over.
It had survived launch, the long coast, the descent burn. And then, in the last moments, on terrain no spacecraft had ever touched, it came down wrong and couldn’t get back up.
I keep thinking about why that place is so unforgiving. At the lunar south pole the sun never climbs overhead the way it does in the photos you grew up with. It skims the horizon at a knife’s-edge angle, all year, so even small rocks throw shadows that run for kilometers, and whole crater floors have sat in darkness for a billion years. A flat patch and a deadly drop can look almost identical when the only light you have rakes across them sideways. It is the strangest lighting any human machine has ever tried to land in.
And it is exactly where everyone wants to go. The permanently shadowed places at the pole are cold enough to have trapped water ice: fuel and air and water for whatever comes next. It is where Artemis III is headed to put people back on the surface. The most valuable real estate in the solar system, and it happens to be the hardest ground we have ever tried to read.
That gap between most valuable and hardest to read is the thing I couldn’t put down.
The question I couldn’t drop
The flight computers that pick landing spots in real time work by geometry. They measure slopes and edges and decide, in seconds, whether the ground below is safe. That logic is fast and proven, and it was built for places where the light behaves. At the south pole the light does not, and the geometry starts seeing cliffs where there are none and smooth ground where there is a hole.
So I started wondering about a different job entirely. Not the split-second decision during descent. Leave that to the engineers who do it for a living. The job before that. Could a machine look at the whole south pole ahead of time, the way a scout reads a map, and quietly rule out the obviously lethal ground so humans only argue about the handful of places that might actually work?
Nobody handed me this. No client, no deadline, no team. Just a blank page, a single laptop, and the free GPUs Kaggle hands out to anyone willing to wait in line. I wanted to find out whether one person could build the whole thing end to end, and whether the result would be worth anything or just confident nonsense.
A video-game Moon taught it about the real one
The first real surprise is also the one I’m still a little smug about.
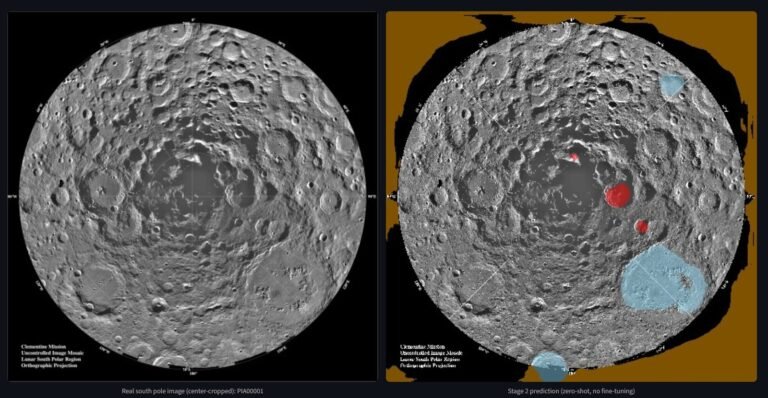
The first job was to teach a model to look at a picture of the lunar surface and label every single pixel: this is rock, this is ground, this is sky. (The jargon for that is "segmentation"; think of it as very patient, very literal coloring-in.) To learn that, a model needs thousands of example pictures a human has already colored in. Real, labeled photos of the Moon’s surface barely exist in that quantity. So the training pictures I used weren’t real at all. They were rendered in a video-game engine, the same kind of software that makes mountains in a shooter. Thousands of fake moonscapes, each with a perfect answer key baked in because the computer drew it.
The obvious worry is that a model raised entirely on a video game learns the video game, not the Moon: that it would ace the fake images and fall apart the instant it saw a real photograph from an actual mission.
It didn’t. I fed it real moon photos it had never seen, with no special coaxing, no retraining, nothing. And it just… worked. It found the rocks. It traced the ground. A stranger looking at the results can’t tell which pictures are the fake training kind and which are real. Something built inside a game engine had learned something true about a real place a quarter-million miles away. I sat there grinning.
It isn’t flawless, and the flaw is my favorite part. Every fake training image had a bright, smooth, uniform sky at the top, so the model quietly invented a rule of thumb: bright and smooth means sky. Usually right. But every so often a big sunlit boulder on the real Moon is also bright and smooth, and the model, very confidently, labels the rock as sky. It’s wrong in the most human way possible: it learned a shortcut that usually works, and gets caught by the exception. I find that charming.
The part that nearly broke me
Then I built the crater detector, and it humbled me completely.
This piece does a different job. Instead of color photos, it reads elevation maps (the shape of the ground itself) and tries to find craters, because a rim or a pit is exactly what you don’t want under a lander. Same plan as before: train it on synthetic data, then point it at the real Moon and watch it shine.
It did not shine. The first time it looked at real lunar elevation maps, it missed the large majority of the craters that were actually there. Not a few. Most of them. It was, plainly, nearly useless: staring at a landscape full of craters and shrugging.
I want to be honest about how that felt, because the tidy version of this story skips it. The first model had worked on the first try and made me feel clever. This one made me feel like I’d gotten lucky and was now being shown the truth. I spent real days in that hole, second-guessing the whole approach, wondering if the project was the kind of thing that demos well and means nothing. The fun part of building something (and I do mean fun, eventually) is the moment the thing that obviously should have worked just… doesn’t, and you have to figure out why.
The why, it turned out, was subtle. The synthetic craters and the real ones weren’t different in kind. They were the same sort of thing, just shaped a little differently than the fakes had taught it to expect. So the fix wasn’t to throw it all out. It was to show the model a small dose of reality: a few hundred patches of genuine lunar terrain, real craters with real labels, and let it adjust. (In the field this is called "fine-tuning": you don’t start a new student over, you let an experienced one apprentice on the real job for a bit.)
That small dose changed everything. The number of real craters it could find jumped by more than double (a 140% improvement) from a model that missed most of them to one that pulls its weight. It’s still not perfect; crater-finding on raw elevation data is hard, and I won’t pretend otherwise. But it went from the thing that nearly made me quit to a piece I trust. That recovery is the part of the project I’m proudest of, precisely because the low was so low.
Ranking 315,000 patches of Moon
With the two "looking" models working, the last stage was the one the project was secretly for: actually picking places.
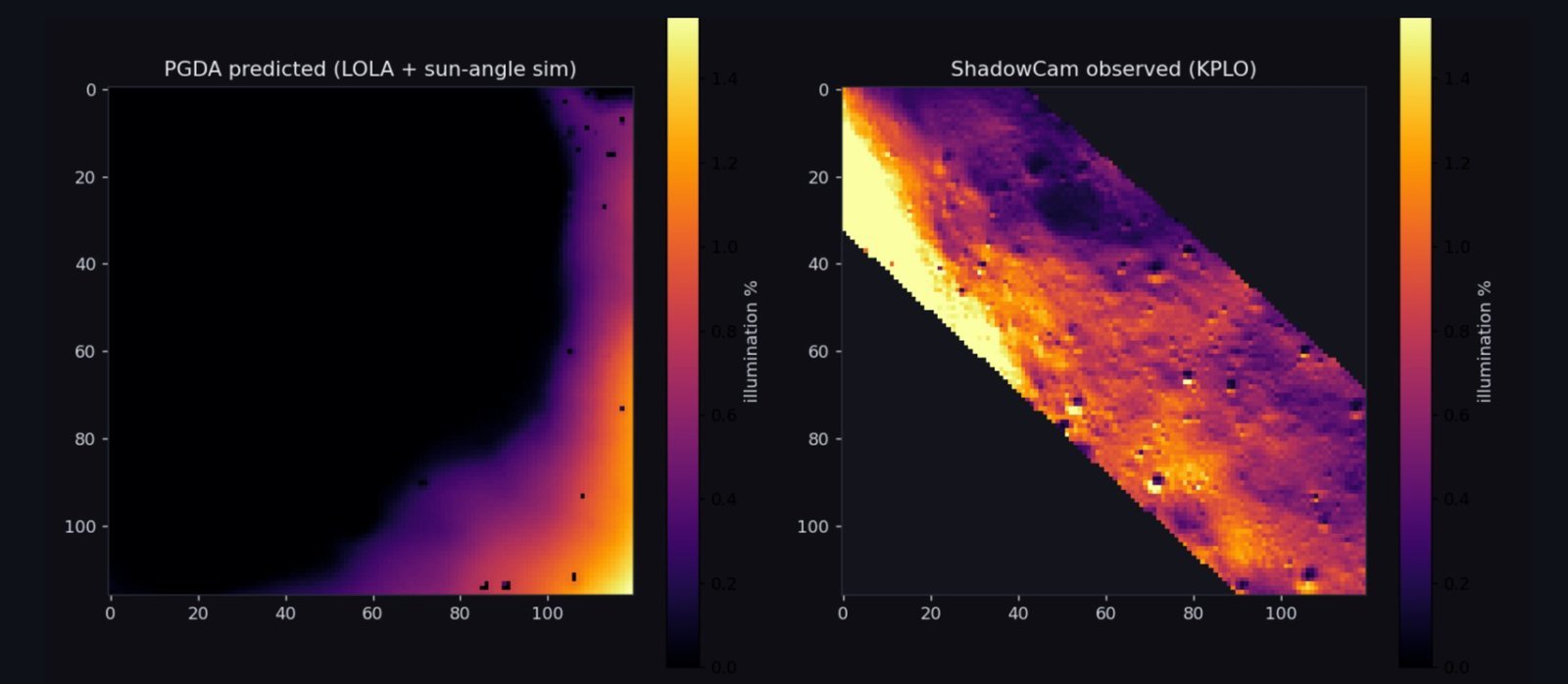
I carved the entire south pole into a grid (over three hundred thousand little square cells, each about a kilometer across) and for every one gathered everything I could measure. How steep is it? How much sunlight does it ever get? Can you see Earth from there, for talking to home? Is it crawling with rocks and craters, from the two models I’d just built? Then I trained a final model to weigh all of that into a single score: how landable is this patch of Moon?
That gives you a ranked list of the whole pole, best to worst. Satisfying. But it raises the obvious, slightly terrifying question: is the ranking any good, or did I just build an elaborate opinion machine?
Here’s the gut-check that mattered to me more than any other moment. NASA, through years of expert work, has publicly shortlisted nine candidate regions for Artemis III. I had never told my model about that list. It had never seen it, never been graded against it. So I asked where its own top picks landed. Five of NASA’s nine regions showed up among them. The model, working alone from raw measurements on my laptop, had independently pointed at the same ground a room full of NASA scientists pointed at. I don’t think I exhaled for a few seconds.
Teaching it to say "I don’t know"
There’s one more piece I care about, and it’s a quiet one.
A model that’s always confident is dangerous, because it’s just as confident when wrong as when right. So I added a way for the model to notice when it’s looking at something truly unfamiliar (terrain weirder than anything it trained on) and to raise its hand and say, in effect, I’m not sure about this one. It’s the difference between an expert who knows the edges of their own knowledge and a know-it-all who bluffs. When the eventual stakes are a real spacecraft and a real crew, I’d take the one who admits doubt every time. Building the humility in felt as important as building the skill.
Knowing when to stop
There’s always another feature. Another model to try, another dataset to chase, another clever idea at 1 a.m. that promises to make everything better. At some point the honest move is to look at a thing that works end to end and call it finished instead of fiddling forever. So I did. The pipeline runs, the parts agree with each other and with NASA, and I’d rather ship something real than polish forever. Stopping was its own small skill to learn.
See it for yourself
If you’d like to poke at it, the whole thing is live and the code is open. Hand it a stretch of the Moon and watch it work: find the rocks, flag the craters, score the ground, and tell you when it isn’t sure.
- Try the live demo: lunarsite.streamlit.app
- Read or fork the code: github.com/AlanSEncinas/LunarSite
If you want the engineering decisions behind all this (the dead ends, the tooling, the forks I argued with myself about), I wrote a separate making-of: the director’s commentary.