Building LunarSite: the director’s commentary
The other half of the story
There are two ways to write up a project like this. One is the results piece: the architecture, the held-out numbers, how it stacks against the benchmark. That version already exists. If you want the metrics table, go read the results write-up.
This is the other one. LunarSite is a solo ML pipeline that screens lunar south-pole landing sites: the kind of pre-mission analysis the IM-2 crash in March 2025 made concrete, when classical geometry aged badly against kilometer-deep shadow and lit peaks ringed by craters.
What I want to talk about is how it got made: the decisions, the forks where I picked one path and parked another, the tooling I built before training anything, the negative result I published so nobody re-runs it. A held-out mIoU tells you what happened; it tells you nothing about the encoder I talked myself out of or the scaffolding that’s the only reason a one-person project this wide shipped instead of dying at 70% in a branch somewhere. Director’s commentary, not the trailer.
Scoping so it actually ships
The biggest risk to a solo project this broad isn’t a hard ML problem. It’s scope. Crater detection, terrain segmentation, a geospatial feature pipeline over 315k grid cells, uncertainty quantification, a dark-terrain story, a live demo. Any one of those is a project. Strung together by one person on a laptop, the default outcome is a half-finished mess where nothing ships because everything is 80% done.
So before I trained a model, I wrote a ship contract. Three layers, each with one done-definition:
- Layer 1: Foundation. Stage 2 segmentation only: a trained segmenter, a sim-to-real qualitative eval, and a Streamlit v0 demo. Done means the core ML capability works and I can show it to someone. That’s it. Not "LunarSite". Just a good lunar terrain segmenter.
- Layer 2: Deepening. This is the real ship. Layer 1 plus Stage 1 crater detection, the Stage 3 XGBoost scorer with LOLA features, deep-ensemble uncertainty on Stage 2, and a Streamlit v3 demo that takes coordinates and returns a site score with SHAP. Done means the end-to-end pipeline works. This is the definition of "LunarSite exists."
- Layer 3: Validation. Layer 2 plus MC Dropout calibrated uncertainty, PSR-aware Stage 3 features from PGDA, and cross-instrument validation against ShadowCam at Cabeus. Done means the pipeline has been checked against something it didn’t train on.
The discipline isn’t in writing those three bullets. It’s in treating Layer 2 as the ship and refusing to let Layer 3’s shiny ideas bleed forward. Calling Layer 2 "the real ship" out loud, in the spec, is a commitment device. When a new idea showed up mid-Layer-1 (and they always do), it had a place to go that wasn’t "start it now."
That place was a BACKLOG. Every "ooh, I should also…" went into a file, not the working tree. A full ShadowCam HORUS denoising pipeline. A DINOv2 encoder swap. LuSNAR supplementary training data. Shadow-from-depth validation against LOLA. All real, all interesting, all written down and not done. The backlog is the pressure valve: it lets you acknowledge the idea (which is what your brain actually wants) without paying for it. Several of those items are still in there, filed under "skipped: low credibility-per-effort." That phrase did more work than any model in this project; more on it in the encoder section.
The other rule was: demo at every layer. Streamlit existed from Layer 1, with cached artifacts so the first paint showed a finished overlay and a per-class IoU table instead of an empty upload box. And each version (Stage 2 only, then the real-moon gallery, then crater output, then the coordinate-to-score flow) was independently shareable. The point is psychological as much as technical: a solo project dies the moment you’re in a "can’t show this yet" position, because that’s when momentum becomes a story you tell yourself instead of a thing on a screen.
The harness before the work
Here’s the decision I’d defend hardest: I built the Kaggle automation before the training it was for.
Free GPUs are great until you count the clicks. The manual loop is: import the notebook, attach the right datasets, set the accelerator, hit Run All, wait, download outputs. About five minutes of browser clicking per run, error-prone in the worst way: the failure mode is forgetting to attach a dataset, which you discover twenty minutes later when the kernel dies on a missing path. Fine once. Not fine when you’re training a 5-seed ensemble, sweeping configs, or re-running an eval for the tenth time after a bug fix.
So scripts/kaggle_run.py wraps the Kaggle CLI and makes every kernel a registered spec. A KernelSpec is a dataclass (slug, title, notebook path, datasets to attach, accelerator, GPU/internet/privacy flags, output dir) and the whole project’s kernels live in one KERNELS dict. The metadata you’d otherwise click into the UI is baked into code, version-controlled, and impossible to forget:
"crater_v2_finetune_seed1": KernelSpec(
slug=f"{KAGGLE_USERNAME}/lunarsite-crater-v2-finetune-seed1",
title="LunarSite Crater v2 Finetune Seed1",
notebook=REPO_ROOT / "notebooks" / "finetune_crater_southpole_kaggle.ipynb",
datasets=[
f"{KAGGLE_USERNAME}/lunarsite-weights",
f"{KAGGLE_USERNAME}/lunarsite-southpole-finetune",
],
output_dir=REPO_ROOT / "outputs" / "crater_v2_finetune_seed1",
),
The subcommands are list, push, status, wait, pull, and run. The first five are the obvious primitives; run earns its keep as the full loop: push the notebook, poll until it finishes, pull the outputs to disk.
def cmd_run(name: str) -> None:
"""Full loop: push, wait for completion, pull outputs."""
cmd_push(name)
print("Waiting for kernel to complete (polling every 60s)...")
final = cmd_wait(name)
if "error" in final.lower():
print(f"Kernel finished with error: {final}")
sys.exit(1)
cmd_pull(name)
cmd_wait polls kaggle kernels status every 60 seconds against a terminal-state set (complete, error, cancelAcknowledged, cancelled) and prints elapsed minutes each tick so you can glance at a terminal instead of babysitting a browser tab. From the command line the whole thing collapses to python scripts/kaggle_run.py run eval_v1_vs_v2.
That is the entire payoff. Training the 5-seed deep ensemble (seeds 2 through 5 are four near-identical entries in KERNELS, two of them generated in a dict comprehension because Kaggle’s slug-from-title behavior forced a naming quirk I only wanted to encode once) became four fire-and-forget commands, not an afternoon of clicking the same five buttons twenty times and praying I attached the landscape dataset each time. The registry doubles as documentation: kaggle_run.py list prints every kernel, its notebook, datasets, and output path. Six months later that’s the only artifact that remembers how crater_v2_finetune was wired.
The principle, and why it belongs in a making-of and not a results piece: if a manual step will happen more than about three times, the tool to automate it is cheaper than the clicking, and cheaper up front, before you know how many runs it’ll take. Building the harness first is a bet that you’ll iterate more than you think, and on a research-shaped project you always do.
Fork #1: the encoder I didn’t use
The original spec called for trying a DINOv2 encoder as a possible Stage 2 v3. On paper it’s the obvious move: a domain-agnostic ViT, self-supervised on a huge corpus, exactly the backbone you reach for when your domain is weird and you want features that don’t assume natural-image statistics. Lunar terrain is about as far from ImageNet as it gets. The pitch writes itself.
I didn’t do it, and I want to be precise about why, because "I didn’t get to it" and "I decided not to" are different statements, and only one is honest here.
The ResNet-34 baseline was already strong, strong enough that the case for the swap was speculative rather than evidenced. I had no signal the encoder was the bottleneck. Sim-to-real transfer was already working: a model trained purely on synthetic Unreal Engine scenes generalized to real moon photography with no domain adaptation, and the class-coverage distribution held up. When the thing you’d replace is already clearing the bar, "a fancier encoder might help" is a hypothesis, not a plan. And a ViT swap is not a cheap experiment: new training recipe, new failure modes, real GPU hours, and a non-trivial chance the answer is "about the same, sometimes worse."
So I weighed it on credibility-per-effort against everything else competing for the same hours, and it lost. The deep ensemble and the MC Dropout calibration delivered better marginal value at lower risk: they make the uncertainty story real instead of making a plot point marginally prettier. DINOv2 went into the backlog under "explicitly skipped," and that’s where it still is.
The thing to flag is that this is not a disproof. I’m not claiming DINOv2 wouldn’t help. I don’t know, because I didn’t run it. It’s a deferral: speculative upside, real cost, a stronger competitor for the same time. On a solo project with finite hours, "I chose not to spend the budget here" is a defensible engineering decision, and pretending every parked idea was secretly bad is just dishonesty with better PR. It might be worth doing later. It wasn’t worth doing instead of calibrated uncertainty.
Fork #2: when the right knobs lose
The most instructive result in the project looks like a footnote on the metrics table: a tiny negative delta. The story behind it is the one I’d want a peer to take away.
For Stage 2, every instinct said the minority classes were the place to push. The classes that matter most for landing safety (small_rocks and large_rocks) are exactly the ones underrepresented in the pixel distribution, dominated by background. Textbook setup for the textbook fixes. So v2 reached for all of them at once: a heavier ResNet-50 encoder for capacity, FocalDiceLoss to down-weight the easy background pixels and focus on the hard minority ones, and inverse-frequency class weighting to rebalance the loss toward the rare classes. Three independently reasonable knobs, all aimed at the same correct-looking target.
It lost. v2 came in at test mIoU 0.8429 with the same flip TTA, 0.0027 below plain v1, which is just a ResNet-34 with vanilla Dice + Cross-Entropy at equal weighting. And it wasn’t a one-eval fluke: stacking multi-scale TTA on top of v2, which should have helped if anything, also degraded it.
The lesson is easy to nod along to and hard to internalize: complexity has to earn its place against a measured baseline, every time, and your priors about which knob should help are not evidence. Three changes that each "obviously" target the right failure mode can still, in combination, land below a baseline that did none of them.
The decision I’m most deliberate about is what I did with the loser: I published it. v2 is up on Kaggle as a documented negative ablation, not quietly deleted. The framing I keep coming back to is the simpler thing won, here’s the data so nobody else has to redo this. That’s useful science, especially when it’s undramatic. Someone else screening lunar terrain will have the same instinct, reach for the same three knobs, and now there’s a public artifact that says: I tried that, here’s the number, spend your afternoon on something else. A results piece reports the winning config; a making-of tells you about the afternoon I spent proving the obvious upgrade was worse, and why I left the evidence out for the next person.
Fork #3: "wrong model" or "wrong data?"
The crater detector is where I almost burned a week on the wrong fix. Stage 1 is a binary U-Net (ResNet-34 backbone) trained on DeepMoon synthetic DEMs; on synthetic validation it was fine. Pointed at real LOLA south-pole tiles, recall fell off a cliff to 0.155, missing roughly 84% of the craters. A screener that finds one crater in six isn’t a detector; it’s a liability.
The instinct is to reach for the model (bigger backbone, fancier loss) because the architecture is the knob you can turn. I made myself name the question first, because the fix differs completely depending on the answer. Two hypotheses: a modality shift, where synthetic and real LOLA DEMs are different kinds of image and the learned features don’t transcribe at all (fine-tuning can’t save you: no shared representation to adapt), versus a distribution-within-domain shift, same modality but the real south pole is a harder, shifted slice: degraded rims, overlapping basins, lighting and scale the synthetic generator never sampled (the features are mostly right and the fix is data).
You tell them apart by ruling out the cheap confounder first. I ran a small grid (four preprocessing configs crossed with nine thresholds) to check whether the gap was just a normalization or scale mismatch fixable at inference. It wasn’t; no config recovered the recall, but the predictions weren’t random either. They fired in the right neighborhoods and dissolved on the degraded rims: the signature of distribution-within-domain, not modality. A model that had never seen this slice would miss diffusely, not fail selectively on the hardest cases. So: don’t change the architecture. Show it the slice.
The fix was 334 real LOLA south-pole tiles: 256×256 patches from LDEM_80S_20MPP_ADJ.TIF, resampled to 118 m/px to match the DeepMoon crater scale, labels from the Robbins 2018 catalogue (craters ≥3 km). Fine-tune, don’t retrain: warm-started from v1, 25 epochs on the 4070. Recall went from 0.155 to 0.372, a +140% improvement, and v2 is the production Stage 1.
Now the honest part, because that number has a cost. IoU here is brutal: my targets are 1-pixel-wide rasterized rims, so a prediction that’s morphologically correct but a few pixels fat scores as mostly wrong, and pushing recall up takes precision down almost mechanically. I took that trade on purpose: for pre-mission screening, a missed crater is a hazard you never knew to avoid, while a thick rim is just a cell you double-check. The point isn’t that 0.372 is triumphant. It’s that I knew which knob to turn, and why.
Why a deterministic rule still needs a model
Stage 3 scores every cell on the south-pole grid, and the landability criteria are, on paper, a hard rule. NASA’s CASSA thresholds are deterministic: slope ≤ 5°, illumination ≥ 33%, Earth visibility ≥ 50%. Three comparisons and a logical AND. So why train a gradient-boosted model on rule-based pseudo-labels? Isn’t that an expensive way to reproduce an if statement?
That objection is right about what the rule is and wrong about what it’s for. The hard threshold gives you a binary mask, and over 315,034 cells × 29 features that mask is useless as a ranking. Under strict CASSA only 419 cells (~0.13%) come back "suitable," and within those the rule says nothing about which is better: a 4.9° cell and a 0.5° cell are both just "pass," a 5.1° cell is "fail," indistinguishable from a 30° cliff. What I want is an ordering: a soft, rankable score that degrades gracefully across the boundary, so a near-miss on one criterion can be redeemed by excellence on the others. That’s what boosting on the pseudo-labels buys: it learns the rule’s shape and interpolates the continuous score the rule can’t give you.
Why not a neural scorer? The data is tabular: 29 hand-built features, the regime where gradient-boosted trees still beat MLPs at a fraction of the tuning. Interpretability is non-negotiable for mission analysis, and SHAP is the trust layer: it lets me say this cell ranked here because of slope and illumination. The validation backs the design: slope dominates the SHAP ranking, which is what every published study finds, so the model rediscovered the field’s known #1 feature on its own.
The dead code that became the uncertainty story
My favorite decision in the project is the one where I wrote almost no new code. A file (src/lunarsite/utils/uncertainty.py) had sat in the tree unused since an early scaffolding pass: real, working MC Dropout helpers (enable_mc_dropout, add_mc_dropout, mc_predict, uncertainty_map_to_rgb) that nothing imported. Dead code. The kind you delete in a cleanup PR.
The interesting bit is add_mc_dropout. segmentation_models_pytorch U-Nets ship without dropout, so flipping eval/train flags gets you nothing, nothing stochastic to enable. This helper walks the module tree and inserts a Dropout2d after every ReLU:
for name, module in model.named_children():
if isinstance(module, nn.ReLU):
setattr(model, name, nn.Sequential(
nn.ReLU(inplace=True),
nn.Dropout2d(p=p),
))
else:
add_mc_dropout(module, p) # recurse
Run that over the ResNet-34 U-Net and it lands 27 Dropout2d modules. At inference, enable_mc_dropout flips just those into train mode while batch norm stays in eval, and mc_predict runs 20 stochastic forward passes, turning their spread into the metrics that matter: predictive entropy for total uncertainty, and mutual information for the epistemic part: does the model know what it’s looking at.
The decision was: resurrect this, don’t train another ensemble. I already had a 5-seed deep ensemble, and the obvious "more uncertainty" move was a sixth and seventh seed. But ensembles and MC Dropout answer different questions. The ensemble gives me disagreement across independently-initialized models (good aleatoric-leaning coverage), but it’s expensive and doesn’t, on its own, tell me whether its confidence is calibrated. MC Dropout gives me a cheap per-pixel epistemic map from one fine-tuned checkpoint. The right move was one of each, not five of one.
That meant fine-tuning from best_resnet34.pt (10 epochs, lr 2e-5, p=0.1) on the 4070 to produce models/best_segmenter_mcdropout.pt, then wiring the helpers into the three call sites: streamlit_app.py, scripts/mc_dropout_calibrate.py, and scripts/train_segmenter.py --mc-dropout. Code that imports nothing is a liability; the work was as much in the call sites as the modeling.
And it paid off in the one way uncertainty work has to: it was honest. Expected Calibration Error came in at 0.0072 across 46 million validation pixels: textbook-calibrated, the confidence means what it says. Better, the epistemic signal pointed the right way out of distribution: on the 72 real moon photographs the model never trained on, mean mutual information ran 4.7× higher than on in-domain validation. That’s exactly the property a screening tool needs: visibly unsure where it’s out of its depth, which on the moon is the shadowed terrain you most need flagged. The best code I shipped in Layer 3 was an import.
Validation as a design choice
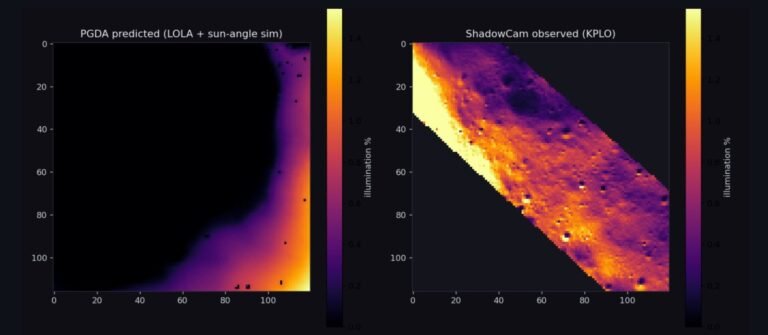
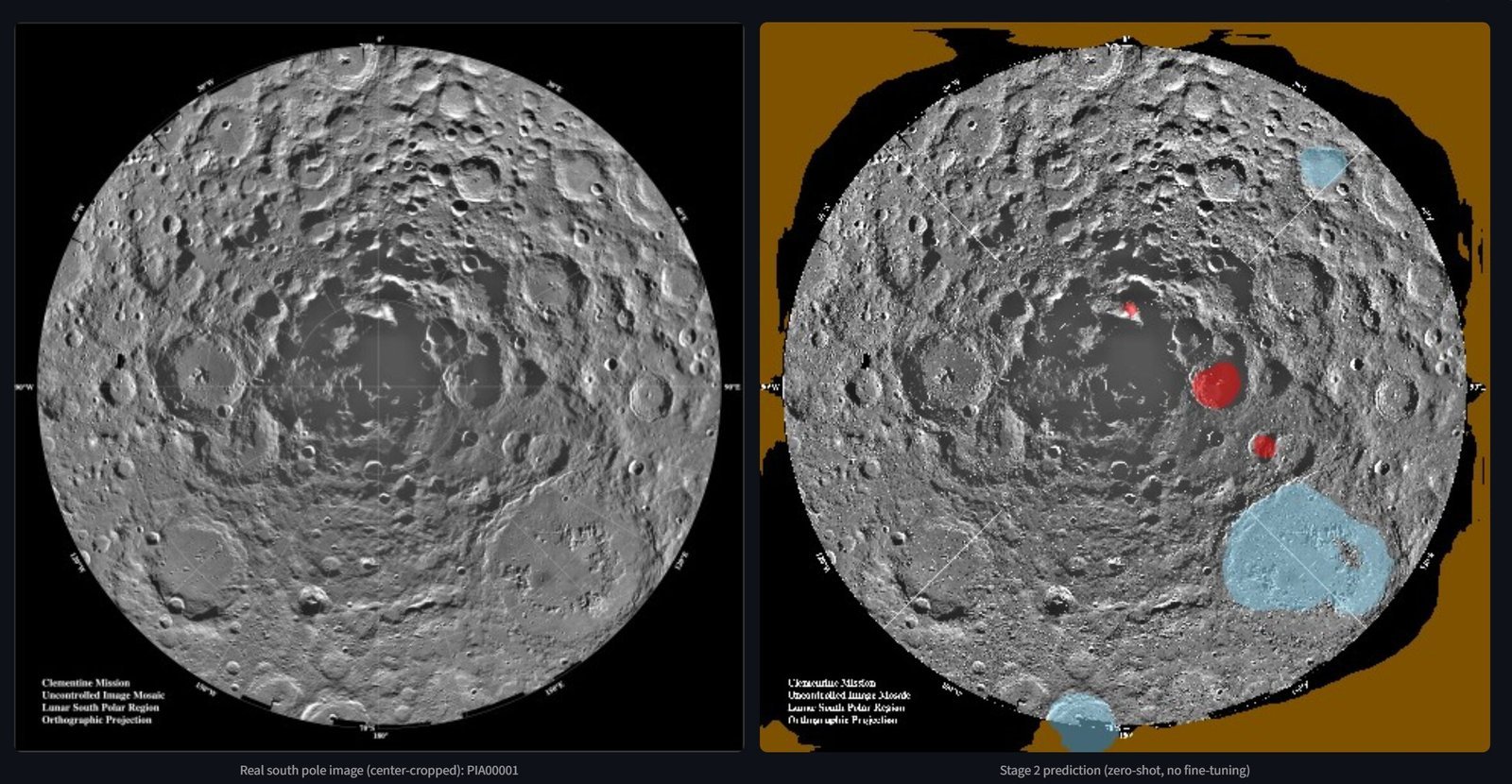
By Layer 3 the tempting move is to grind another tenth of an mIoU point. I didn’t, because an internal metric improving is the least convincing thing you can show a skeptic: you chose the metric and the split. So I spent that budget on two external yardsticks I didn’t get to define. First, overlap with NASA’s Artemis III shortlist, a human-curated list from a completely different process: my top 1,000 cells hit 5 of the 9 regions, Mons Mouton dominating. Second, a cross-instrument check against ShadowCam, a separate sensor with separate physics: at Cabeus, 81–85% of its deepest-observed-shadow pixels fall inside my PGDA-predicted PSRs. And the screener excludes them on its own, 0 of the top 100 cells containing permanently-shadowed ground. Agreement with an independent shortlist and an independent instrument buys credibility no internal tuning can, because I couldn’t have rigged either.
The cuts, and the judgment behind them
I want to be straight about what I left out, because the cuts are a design decision too. HORUS-style PSR denoising, the LuSNAR supplementary training set, the DINOv2 encoder revisit, shadow-from-depth validation against LOLA, all parked under one phrase: low credibility-per-effort. Each would move a number; none would change the story. HORUS needs the raw 19 GB ShadowCam cubes to validate properly, for a marginally cleaner image; LuSNAR is 108 GB to maybe nudge an mIoU already clearing the bar. A cut isn’t an omission when you can name exactly what it would and wouldn’t buy you. It’s triage. The skill on a solo project isn’t doing everything; it’s saying why not.
What I’d do differently
If I ran it again: I’d diagnose modality-vs-distribution before training Stage 1, not after a recall of 0.155 forced the question. The synthetic-to-real gap was foreseeable and I paid in a re-train I could have skipped. I’d write the calibration eval before the ensemble, because I built five seeds before I had a way to ask whether any were calibrated. And I’d treat dead code as deferred code from day one; the MC Dropout helpers were the project’s best ROI and nearly got swept in a cleanup. The throughline: the leverage on a project this wide isn’t the models, it’s the order you ask the questions.
If you want the story without the engineering weeds, I wrote the narrative version. For the full numbers, see the results write-up.